library(keras)
install_keras()Training neural networks
Pre-lab activity
Please complete this activity before arriving at your section meeting. It should only take you about 15 minutes.
Python installation
We will use packages that interface to python from R to train neural networks in this lab. For this a current python installation is needed.
Select the download appropriate for your operating system here and follow installation instructions.
Keras and Tensorflow
Open RStudio and execute the following commands in the console. You should have already installed keras with other packages in the first lab; however, if library(keras) returns an error execute install.packages('keras') and then try again. This will install Tensorflow (for python) in a manner suitable for use in R, along with a few other packages.
To confirm the installation worked, try:
library(tensorflow)
tf$constant('Hello world')tf.Tensor(b'Hello world', shape=(), dtype=string)You may see a long message related to CUDA libraries in addition to the output shown above, but if you see this output at the end, your installation was successful.
If you did not see the expected output, try configuring a virtual environment for the installation explicitly as shown here.
If you are unable to troubleshoot after a short period of time, partner with a classmate for the lab activity and then ask for help from course staff.
Lab activity
Setup
Action
Setup
Open a new script for this lab, copy-paste the code chunk below at the top of the script, and execute once.
# packages
library(tidyverse)
library(tidymodels)
library(tidytext)
library(keras)
library(tensorflow)
# data location
url <- 'https://raw.githubusercontent.com/pstat197/pstat197a/main/materials/labs/lab6-nn/data/claims-clean.csv'
# read in data
clean <- read_csv(url)Now partition the data into training and test sets.
Action
Data partitioning
- Copy the code chunk below into your script but do not run the resulting lines.
- Coordinate with your neighbor: choose a new RNG seed and split proportion and input the same values in each of your scripts.
- Execute lines to partition the data.
# partition
set.seed(102722)
partitions <- clean %>%
mutate(text_clean = str_trim(text_clean)) %>%
filter(str_length(text_clean) > 5) %>%
initial_split(prop = 0.8)Now use the code chunk below to preprocess the training partition into a TF-IDF document term matrix (DTM), as before.
train_dtm <- training(partitions) %>%
unnest_tokens(output = 'token',
input = text_clean) %>%
group_by(.id, bclass) %>%
count(token) %>%
bind_tf_idf(term = token,
document = .id,
n = n) %>%
pivot_wider(id_cols = c(.id, bclass),
names_from = token,
values_from = tf_idf,
values_fill = 0) %>%
ungroup()Logistic regression as NN
To get a feel for keras, first we’ll fit a logistic regression model.
Recall that in class it was mentioned that standard statistical models can be described by neural networks with no hidden layers; along these lines, standard statistical models can also be fit using optimization routines for neural network training.
Use the code chunk below to get the TF-IDF values for the (alphabetically) first ten tokens. We’ll use these as predictors.
# extract first ten features
x_train <- train_dtm %>%
ungroup() %>%
select(-.id, -bclass) %>%
select(1:10) %>%
as.matrix()
# extract labels and coerce to binary
y_train <- train_dtm %>%
pull(bclass) %>%
factor() %>%
as.numeric() - 1This is purely for illustration purposes; any model using these variables should not perform well at all because ten tokens won’t contain much information about the classes.
To use keras, we’ll go through a few steps that are generally not done separately for fitting statistical models:
Model specification, i.e.,defining an architecture
Model configuration, i.e., specifying a loss function and fitting method
Model training, i.e., computing estimates for the parameters
Model specification
Model architecture is defined layer-by-layer. Keras has some preconfigured model types: for feedforward networks, use keras_model_sequential() .
# specify model type
model <- keras_model_sequential(input_shape = 10)The input_shape argument specifies the number of units for the input layer – in other words, the number of predictors.
At this stage, the model is just scaffolding:
summary(model)Model: "sequential"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
================================================================================
Total params: 0
Trainable params: 0
Non-trainable params: 0
________________________________________________________________________________Now layers can be added one-by-one. For now we’ll just add an output layer – one unit. layer_dense will specify that the previous layer is fully-connected to the added layer.
# add output layer
model <- model %>% layer_dense(1) The model summary now shows the output layer.
summary(model)Model: "sequential"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
dense (Dense) (None, 1) 11
================================================================================
Total params: 11
Trainable params: 11
Non-trainable params: 0
________________________________________________________________________________Lastly, we’ll add a sigmoid activation function:
model <- model %>%
layer_activation(activation = 'sigmoid')Since there is no hidden layer, our model is
Notice that this is the logistic regression model (without the distributional assumption).
Model configuration
Configuring a keras model consists in equipping it with a loss and an optimization method. Optionally, metrics that you’d like computed at each training epoch can be included.
model %>% compile(
loss = 'binary_crossentropy',
optimizer = optimizer_sgd(),
metrics = 'binary_accuracy'
)This says that to train the model, we’ll minimize binary cross-entropy on the training data using stochastic gradient descent.
To train for 10 epochs, pipe the model into fit() and supply the training data. Note that the training data must be numeric, not a data frame.
history <- model %>%
fit(x = x_train,
y = y_train,
epochs = 10)The following commands will retrieve weights, evaluated loss ans specified metrics, and predictions.
# retrieve weights
get_weights(model)[[1]]
[,1]
[1,] -0.309943348
[2,] -0.607303262
[3,] -0.684534788
[4,] 0.080475129
[5,] -0.047711506
[6,] 0.232125387
[7,] -0.203573957
[8,] -0.295428514
[9,] 0.001397455
[10,] -0.489086449
[[2]]
[1] 0.02782592# evaluate on specified data
evaluate(model, x_train, y_train) loss binary_accuracy
0.6928954 0.5226244 # compute predictions
model(x_train) %>% head()tf.Tensor(
[[0.49740595]
[0.5064572 ]
[0.506311 ]
[0.5053739 ]
[0.5067238 ]
[0.5057194 ]], shape=(6, 1), dtype=float32)
Action
Check your understanding
Discuss with your neighbor:
- How many parameters does this model have?
- Do the number of parameters match your expectations?
- Why will the parameter estimates not match the result of
glm()? - Would further training epochs improve the performance?
Single-layer network
Now that you have a sense of the basic keras syntax and model specification/configuration/training procedure, we can train a proper network with one (or more!) hidden layers.
First coerce the DTM into the format needed for training.
# store full DTM as a matrix
x_train <- train_dtm %>%
select(-bclass, -.id) %>%
as.matrix()Now configure a model with one hidden layer having 10 units. Notice that the architecture can be defined by one sequence of pipes rather than stepwise as before.
model <- keras_model_sequential(input_shape = ncol(x_train)) %>%
layer_dense(10) %>%
layer_dense(1) %>%
layer_activation(activation = 'sigmoid')
summary(model)Model: "sequential_1"
________________________________________________________________________________
Layer (type) Output Shape Param #
================================================================================
dense_2 (Dense) (None, 10) 176540
dense_1 (Dense) (None, 1) 11
activation_1 (Activation) (None, 1) 0
================================================================================
Total params: 176,551
Trainable params: 176,551
Non-trainable params: 0
________________________________________________________________________________Notice the number of parameters. (Does this match your expectation?) Configure the model:
model %>%
compile(
loss = 'binary_crossentropy',
optimizer = optimizer_sgd(),
metrics = 'binary_accuracy'
)And finally, train:
history <- model %>%
fit(x = x_train,
y = y_train,
epochs = 50)
plot(history)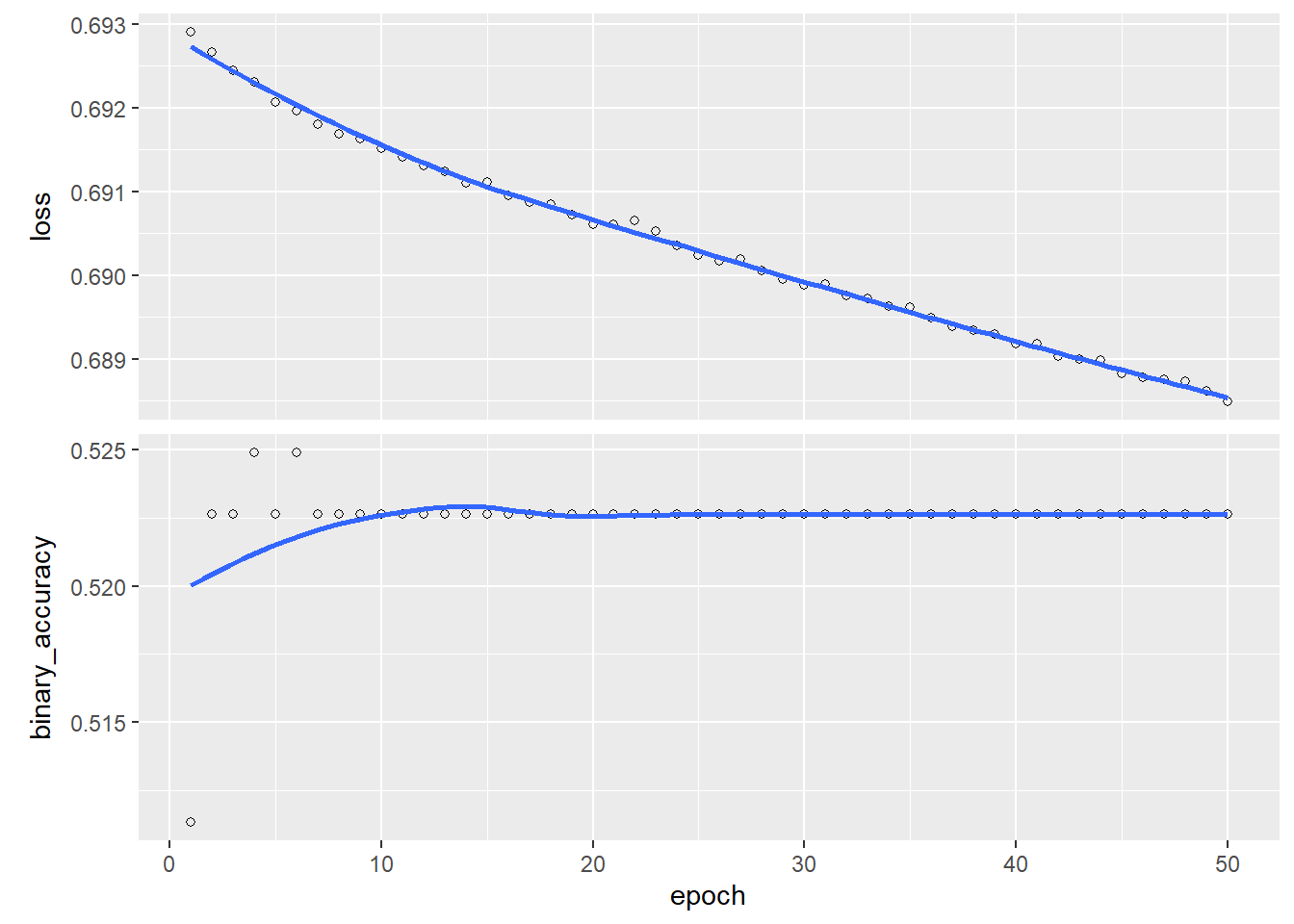
Notice that even after 50 epochs the results are still quite poor. As mentioned in class, the choice of optimization method can have a big impact on the quality of estimates. If we train the model instead using Adam, good accuracy is achieved after just a few epochs:
# change the optimizer
model %>%
compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = 'binary_accuracy'
)
# re-train
history <- model %>%
fit(x = x_train,
y = y_train,
epochs = 10)
plot(history)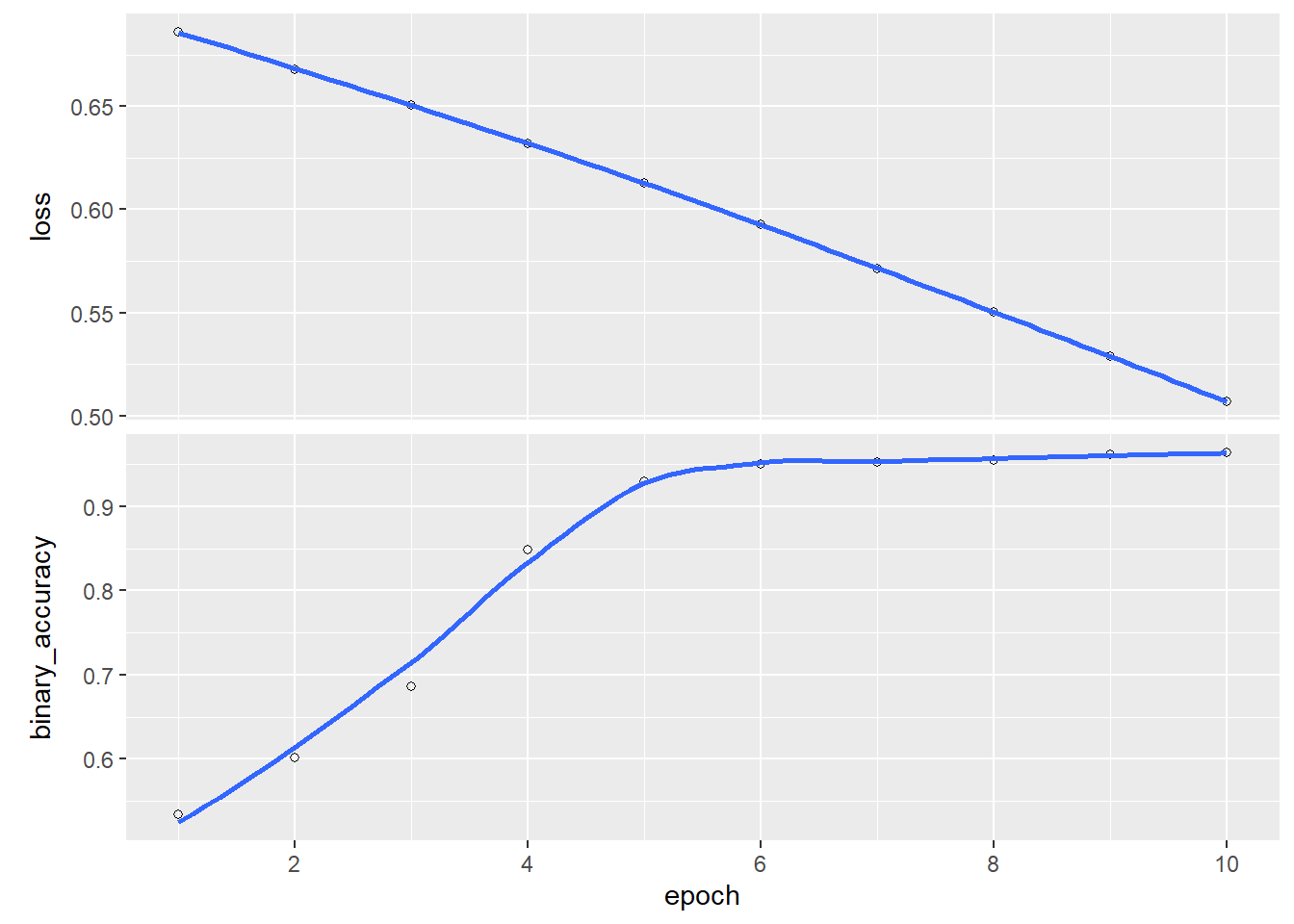
Validation data
Often training data are sub-partitioned into training and ‘validation’ sets. The validation set can be used to provide a soft estimate of accuracy during training.
This provides one strategy to avoid overfitting – the practitioner should only train as long as validation accuracy continues to increase.
Keras makes that easy by supplying an extra argument to fit(). The code chunk below trains for longer and uses 20% of the training data for validation. You should see that the training accuracy gets quite high, but the validation accuracy plateaus around 80%.
# redefine model
model <- keras_model_sequential(input_shape = ncol(x_train)) %>%
layer_dense(10) %>%
layer_dense(1) %>%
layer_activation(activation = 'sigmoid')
model %>%
compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = 'binary_accuracy'
)
# train with validation split
history <- model %>%
fit(x = x_train,
y = y_train,
epochs = 20,
validation_split = 0.2)
plot(history)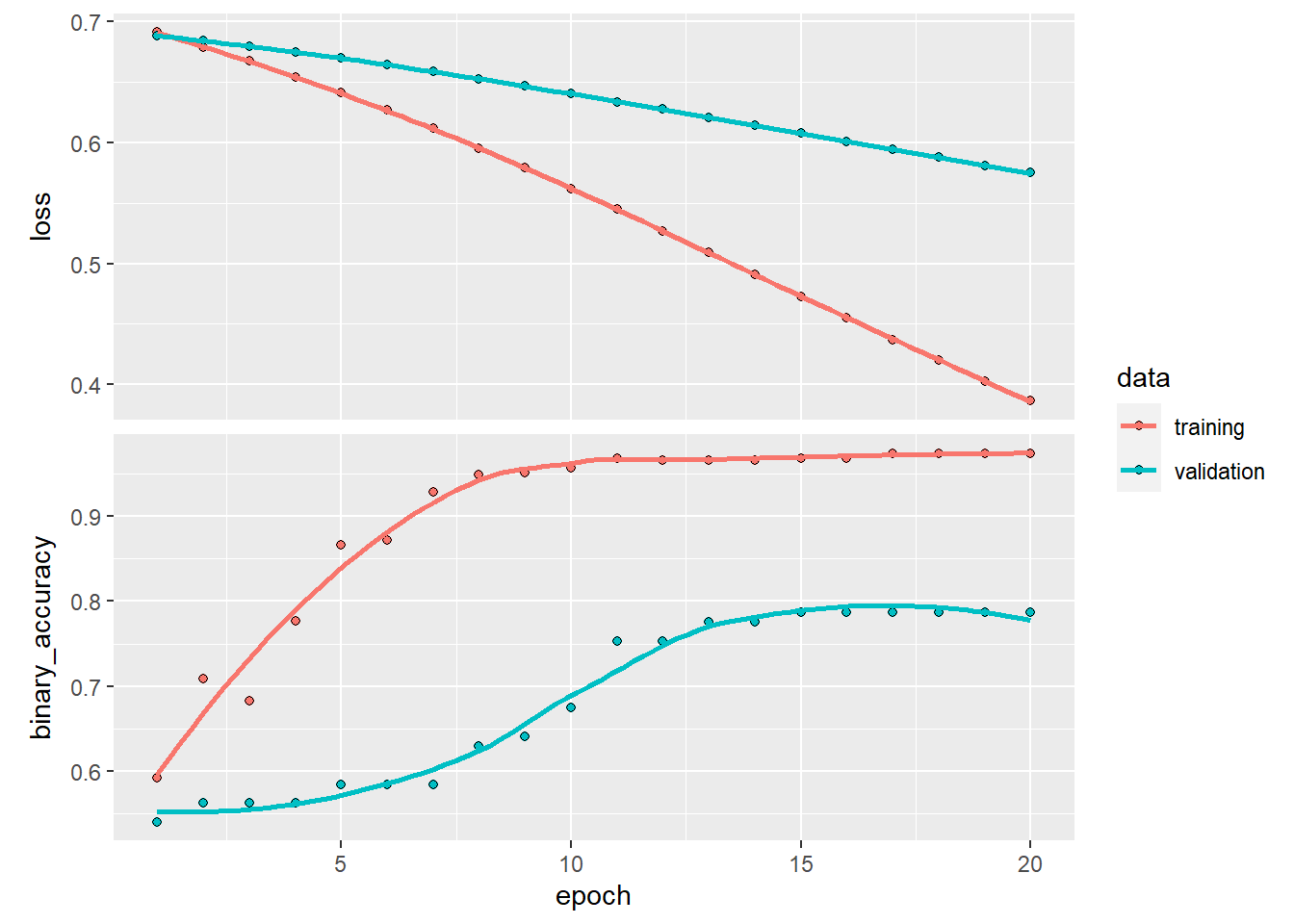
Action
Compute predictions from your trained network on the test partition. Estimate the predictive accuracy. Is it any better than what we managed with principal component regression in class?